Debugging SAC Implementations in ten Pull Requests (or less)
During the last semester I was working on a research project, where we combined Curriculum Learning with Domain Randomization to increase Sim-To-Real performance without lengthy data acquisition involving the targeted platform. Part of this work involved the open-source Reinforcement Learning library SimuRLacra, which was written by my supervisor and provided us with the necessary algorithms and environments on which we could implement and test our idea.
Unfortunately, the provided Soft Actor Critic (SAC) implementation was not working as well as it should (meaning not at all 😅). Debugging this led me down an interesting but also frustrating path, which I want to recount here together with their appropriate pull requests. So get ready for a deep dive into one of the weirdest (and longest) debugging sessions I ever had.
Step 1 (kinda): What Magic Numbers should I use?
Why only kinda? Well, the usual way to debug a problem in anything related to machine learning is to fiddle with the hyperparameters of the model until you see something. If you have ever worked with SAC you probably know this table, which shows a certain choice of them made by the creator of the algorithm himself1.
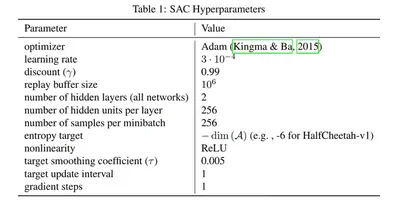
While they form a good starting point, they are also not optimal to every application and especially not to every implementation of SAC. So usually it requires a lot of guesswork to find good hyperparameters to your problem (except when you are one of FANG, where computing time is free™️). I don’t think that this process is particularly interesting and since it also did not work I am skipping it and move on to the next step in the process:
Step 2: Is it you or is it me? - Finding a baseline
After trying this approach for a long time together with my advisor we decided that it is probably not the correct choice of the “magic numbers” but something else in the implementation or the environment. Since we had algorithms able to solve the environment (e.g. a working PPO implementation), it was probably the former of the two. Following this logic it seemed a good idea to test whether other implementations of SAC would perform similarly on the same task and environment.

Some of the best implementations of a lot of common algorithms are provided by the stable-baselines project. Unfortunately, they require a specific interface to the environment such that their implementation can communicate and control without having to be adapted to every new environment. While this interface, the openai gym is fairly standardized, it still required some work to adapt to SimuRLacra’s specific implementation of the Quanser Qube2.
So my first pull requests was the creation of an interface between SimuRLacra and gym.
After everything in place I was now able to use the implementation of SAC provided by stable-baselines with our environment and see how well it performs.
Step 3: Initialization is Key(-ming)
Running a few experiments with the stable-baselines implementation turned out to be eye-opening. Not only did it run much faster than the implementation provided by SimuRLacra, it also actually solved the task instead of stopping at a sub-optimal solution. To add further insult to injury it did all this without any changes to the default hyperparameters, which made the previous weeks look like a lot of wasted time on my end 😢. Looking at these results I decided to investigate further, trying to find out why there is such a mismatch between these two implementation.
One of the first avenues I took in debugging this problem were the neural network architectures of both implementations. SAC uses two neural networks called actor and critic, which are trained together. Their roles can be inferred from their names: While the actor proposes an action and the critic judges it and provides the feedback to the actor. Both are usually trained together 3 and there are a lot of interdependencies between them, which can be encoded into the architecture of the underlying networks4.
In my case I was looking into such a structural difference to explain the initial performance gap: Without any training, the stable-baselines implementation outperformed the one provided by SimuRLacra significantly. As it turned out however, both implementation did not differ that much in their architectural choices, those being size and activation functions. It took me some time and looking at a lot of gradients to find one major difference: Initialization.
From my perspective there is not that much talk about neural network initialization in the supervised and unsupervised space5, but even less in the area of reinforcement learning. This is quite curious, since a good initialization can make or break a good experiment run due to its influence on the initial exploration of the agent. However, many RL frameworks just defer to the standard initialization provided by the underlying library like pytorch or tensorflow and do not make any explicit changes to it. This was not the case for SimuRLacra however.
While SimuRLacra usually follows the conventions of pytorch, it did differ significantly in the case of initialization. Instead of just using the defaults, initialization was done explicitly, inspired by the “current” implementation of pytorch. But this code was not updated in some time and while pytorch moved on to use the Kaiming initialization 6, SimuRLacra just did not. I therefore adapted the current code to follow pytorchs path, leading to the second pull request (which technically came after the first one, but that is just the order I opened them in, not the order they were created).
And that had a huge impact! Not only in the case of SAC, but also for other algorithms like PPO the performance increased significantly.
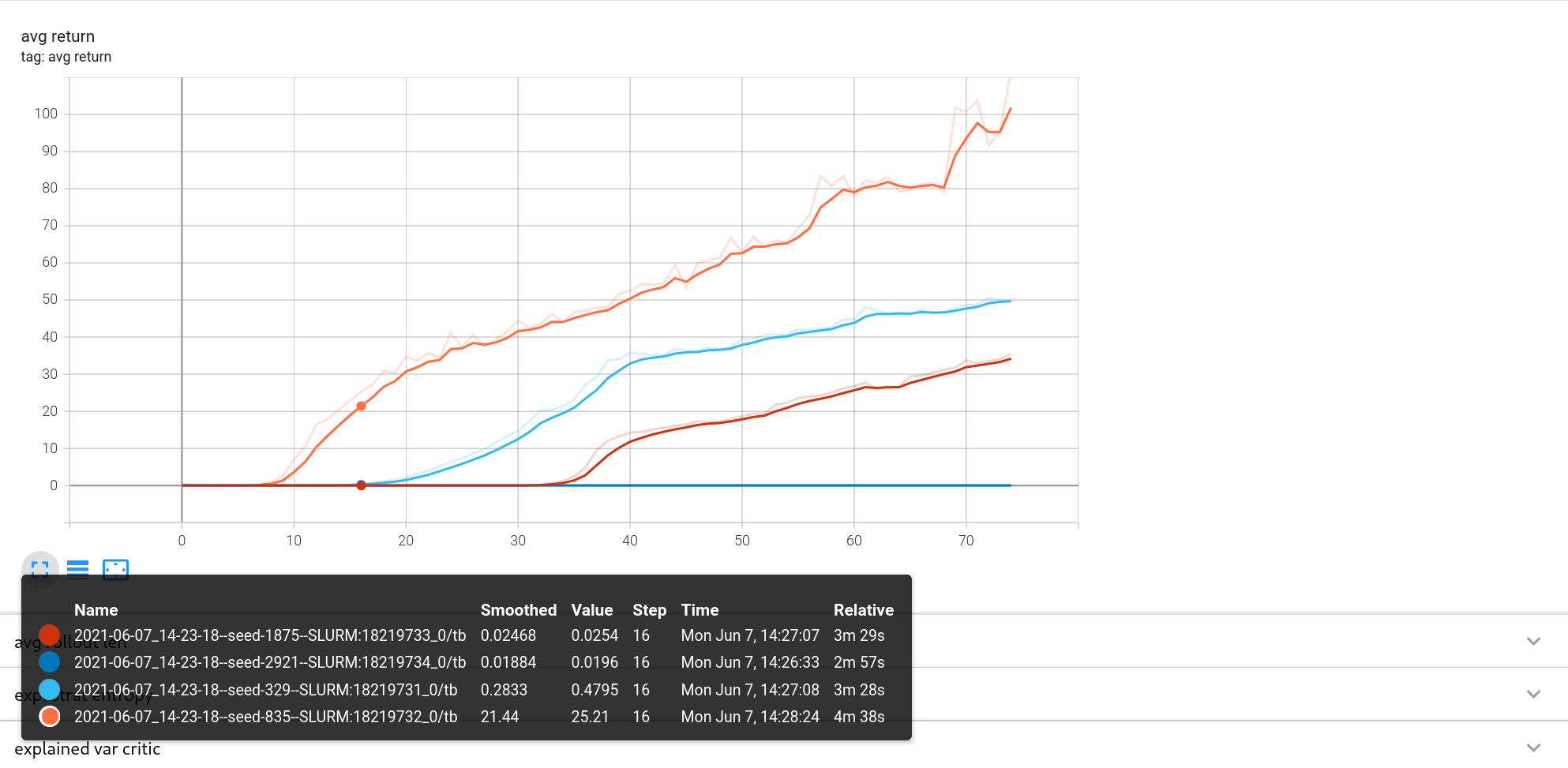
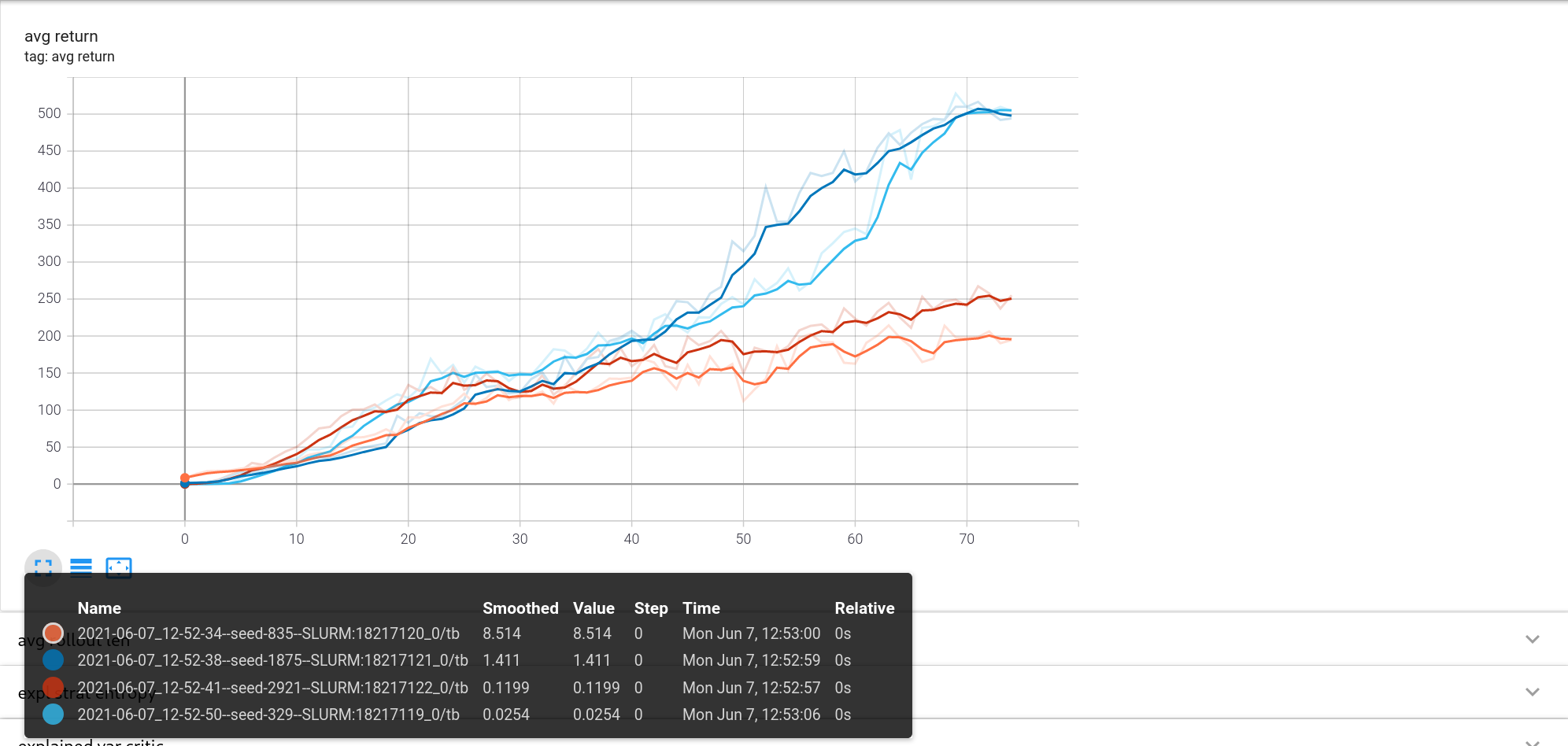
While this moved the SimuRLacra implementation closer to the stable-baselines one, it did not bring it up to par in regards of later performance: Still the task was not being solved, but at least the intermediate performance looked promising.
Step 4: What to remember?
I want to write a blog post about the underlying project (Self-Paced Domain Randomization) at some point, so I won’t get into too much detail here regarding the intricacies of this specific application. Do understand the next step, however, I will give a short intro to Curriculum Learning.
To be continued
Haarnoja et al., Soft Actor-Critic Algorithms and Applications ↩︎
The gym interface is also not really documented and the missing type annotations make the implementation a little bit of guesswork and trial and error. ↩︎
But not directly updated together in the case of SAC ↩︎
For example you can have actor and critic share the same (learned) feature transformation ↩︎
That does not mean that initialization is a widely disregarded topic; far from it. I just want to point out that it is often glossed over in RL literature. ↩︎
He et al., Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification ↩︎